¶ Functional Scope
The functional scope of the platform includes:
- Aggregation
- Managing
- Processing
- Storage
of health data from different sources.
¶ Primary goal
Create a basic foundational technology layer suitable for any digital health application providing better interoperability, portability, availability, analysis, security of the data.
¶ Use Cases
- EHR Systems for healthcare providers
- User-centered dashboards for personal health management
- Data sharing with doctors, health coaches, or family members
- Decentralized clinical trial platforms (e.g. BYOD wearable)
- Patient recruitment services for clinical trials
- Citizen science platforms
- Health data marketplaces
- Open health databases for research
- Algorithm and scores development (e.g. in-silico trials)
- Niche health applications with specific requirements or custom integrations
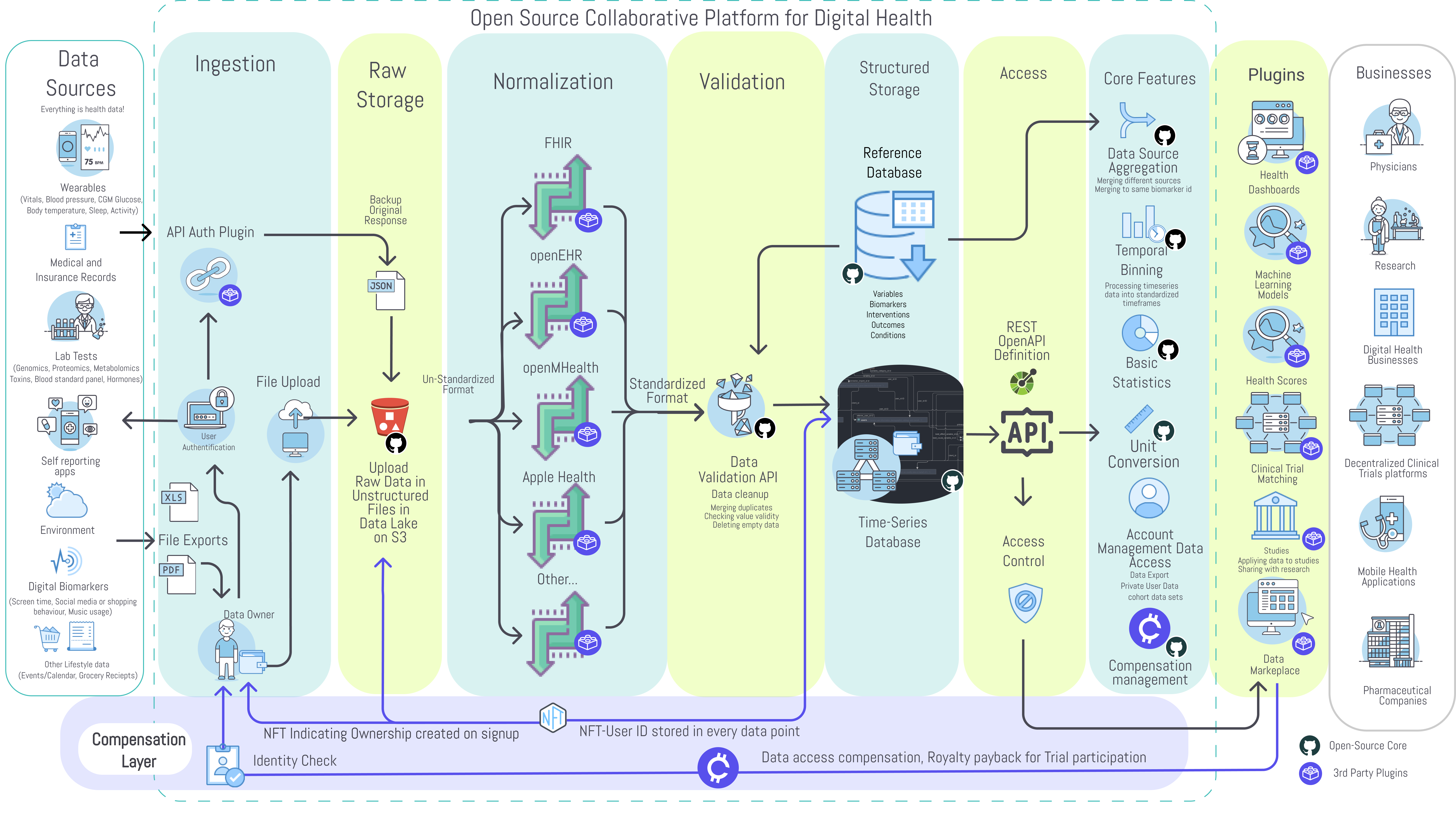
The platform consists of two primary components:
- Core Open-Source Platform - The core platform is open-source and includes only universally necessary features. This primarily consists of user authentication, data owner access controls, data storage, data validation, and an API for storage and retrieval. The DAO will compensate contributors to the core platform.
- Plugin Framework - Plugins are modules that provide additional functionality. This includes data import from specific sources, data mapping to various formats, data analysis, data visualization, notifications. These may be free or monetized by their creator or even be integrated into the core based on community voting.
¶ 3.1 Core Components
¶ 3.1.1 Data Ingestion API
In theory, any kind of human-generated data which can be ingested and used for deriving health insights should be defined as health data and be made accessible for further analysis.
The challenge is to acquire, extract, transform, and normalize the countless unstandardized data export file formats and data structures and load them into a standardized structure that can be easily analyzed.
Proposed is the development of an application programming interface (API) and OpenAPI specification for receiving and sharing data with the core database. Software development kits (SDK’s) made available for 3rd party applications allow the interaction with the API. SDK’s will enable developers to implement easy automatic sharing options in their applications.
Separate plugins will enable spreadsheet upload/import and scheduled imports from existing third-party APIs. The API connector framework will allow the ongoing regular import of user data after a single user authorization.
¶ Data Sources
- Laboratory and Home tests (Standard Blood panels, Metabolomics, Proteomics, Genetics, Urinalysis, Toxins, etc)
- Wearable (Sleep and Fitness trackers, etc)
- Health apps (Meal tracking, Fertility, etc)
- User reported symptoms and intervention application
- Electronic Heath Records
- Imaging
- Questionnaires
- Functional tests
- Environmental and context data (Twosome)
- Life events, Calendar, Social media, and Lifestyle
- Digital biomarkers
- Location
¶ Data Formats
- FHIR
- openEHR
- LOINC
- SNOMED
- RXNORM
- MedDRA
- ICD-10
- Open mHealth
¶ EHR Policies
- CMS Interoperability and Patient Access Final Rule
- CMS Interoperability and Prior Authorization Proposed Rule
- Guidance for States
- Best Practices for Payers and App Developers
- Patient Privacy and Security Resources
¶ EHR Technical Standards
¶ Implementation Support for EHR APIs
| API Name | Supporting IGs |
|---|---|
| Patient Access API | The CARIN Consumer Directed Payer Data Exchange IG (also referred to as the CARIN IG for Blue Button®) HL7 FHIR Da Vinci PDex IGHL7 US Core IG HL7 FHIR Da Vinci - PDex US Drug Formulary IG |
| Provider Access API | * See Above IGs for Patient Access API |
| Payer-to-Payer API | * See Above IGs for Patient Access API |
| Provider Directory API | *HL7 FHIR Da Vinci PDex Plan Net IG |
| Documentation Requirements Lookup Service API | HL7 FHIR Da Vinci - Coverage Requirements Discovery (CRD) IG HL7 FHIR Da Vinci - Documentation Templates and Rules (DTR) IG |
| Prior Authorization Support (PAS) API | *HL7 FHIR Da Vinci - PAS IG |
| Bulk Data | *HL7 FHIR Bulk Data Access(Flat FHIR) Specification |
¶ 3.1.2 Raw Data and Files Storage
To preserve originality in case of data processing errors or protocol changes the ingested raw files like CSV files, PDF reports, and the raw API responses are stored separately in a binary data and file storage system. Data will be encrypted and stored in its raw format in flat files on a secure cloud provider defined in the framework instance platform settings. Preservation of the data in its original format will allow for:
- Asynchronous Queued Data Parsing Jobs - This is necessary to allow for the data to be parsed in parallel offline and avoid overloading the observer.
- Storage of data incompatible with a time-series relational data store.
- Storage of data formats that do not yet have defined parser plugins. This will allow for the data to be imported at a later date when the data mapper has been defined.
- Updating parsers to support changes in the response format for a particular API.
The original raw data and files can be accessed at any time by the owner, independently from any other process involved with the structured data storage.
¶ 3.1.3 Data Mapping
To make the standardized structured storage of health data and the envisioned queries possible, the data has to be ingested from files or API requests and mapped from many different standards and proprietary formats into a standard schema. These will be executed in an asynchronous queue to map the raw data to a standardized format and provide it to the validator. The most common data mappers will be integrated into the core. Less common data mappers will be available as plugins from 3rd party developers.
Core data mappers (Initial proposal):
- FHIR
- LOINC
- SNOMED
- RXNORM
- OpenEHR
The database schema will be consistent with existing formats while addressing some gaps of missing definitions. The goal of a simplified, universal standard format is to make multi-omics data as well as environmental, social, digital biomarkers easily analyzable.
¶ 3.1.4. Data Validation
In order to ensure a level of quality required by healthcare and clinical trials, data quality and consistency must be ensured. The data validation middleware will validate the data before it is stored in the time-series database.
Validation involves the following steps:
- Ensure values are within allowed ranges for a variable and unit
- Outlier detection
- Strict data type checking for all properties
Invalid Data Handling:
- Data deviating from allowed value ranges will be flagged for review and deletion or correction
- Outliers will be be flagged
- Invalid data types will be ignored and the data ingestion plugin developer will be notified
- Duplicate data for a given timestamp will be ignored and the data ingestion plugin developer will be notified
¶ 3.1.5. Reference Data Definitions
Mapping data from different formats into one standardized format suitable for a measurements analysis requires a reference database with tables of definitions and descriptions to be used by the data mappers and by the API for displaying this information in applications. The type of data to be defined includes biomarkers, health-related variables of any kind, interventions, therapies, outcomes, conditions, etc.
Examples of currently used existing reference databases include LOINC, RXNORM, ICD-10 but are partly not suitable enough and have to be unified for the scope of more efficient data handling and analysis. Especially definitions for environmental factors, natural supplementation or therapies, digital biomarkers, and social and lifestyle data sources have a lack of integration.
The proposed solution for overcoming challenges with interoperating with data formats like FHIR is a single measurements table with all definitions query-able by beforehand mentioned categories and types. The main reason for this solution is the complexity of the nature of the definition of a health-related measurement.
Often a variable can be either be both an input factor or a health outcome with respect to the black-box system human body. Thus, whether or not a variable is a controllable input factor and/or a health outcome is stored in the variable settings table. All measured values are thrown in one "pool" and can be retrieved in a flat universal format without having to worry about transforming complex nested data structures for compatibility.
Units of Measurement
The Unified Code for Units of Measure (UCUM) system will be used to include all units of measures being contemporarily used in international science. The full list of units of measure is available here.
¶ 3.1.6. Time Series Data Storage
After validation and mapping, the data will be stored in a standardized and structured time-series database.
Functional Requirements:
- Large scale data storage for time-series data
- Standardized format
- Safety and Security
¶ 3.1.7. Data Ownership
Data should be owned by the individual who generated it. It should remain under their control throughout the entire data life-cycle from generation to deletion. The data owner shall have the unrestricted ability to manage their digital health identity.
Ownership management functionalities will allow the individual to manage their data and access control settings for sharing purposes. It will allow them to:
- View and Access their data
- View the OAuth clients with access to the data
- Modify read/write permissions for specific OAuth clients
- Restrict data access to specific users, groups, researchers, or applications
- Restrict data access to specific data categories, types, and markers
- Restrict time and expiration of data access
- Configure security measures such as encryption or 2-factor authentication
- Overview of statistics of data (amount, averages, sources, etc..)
- Export stored data or the original files
- Delete data
This feature can be used by user-centered applications and dashboards for personal health management, for data sharing with care providers, research, or for participation in trials.
¶ 3.1.8. Data Compensation
Health data is a sensitive and valuable commodity.Therefore the handling of the data alongside its attached value is proposed to be built natively into the core. Value stream management functionalities will allow the exchange from data against tokenized value assets in different scenarios. It will allow:
- Individuals to share data and receive defined compensation
- Groups create and attach insights from grouped data sets to values and exchange to buyers against value assets
- Researchers apply, formulate and visualize values of data sets
- Connect data to value in general for administration purposes
- Applications to create a value-based feedback loop for research or behavioral outcomes
Data Value Scenarios:
- Raw data sets or streams of individuals
- Cohort raw data sets of grouped individuals
- Interpreted data, scores, and recommendations
- Generated insights and IP out of data analysis
- Specifically aggregated data according to requested needs from buyers
- Phenotypic, demographic, lifestyle, conditions, environmental context
This feature can be used for exchanging data on marketplace applications or clinical trial platforms.
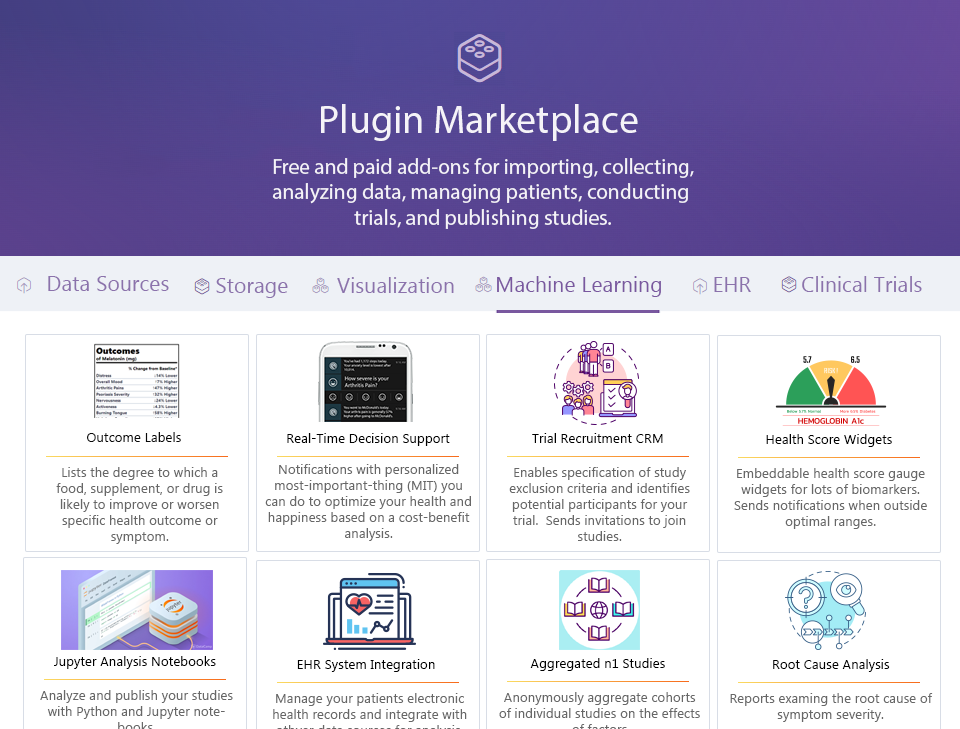
¶ 3.2 Plugins
Defined interfaces will allow 3rd party development of software modules that interact with the core and provide additional functionality. They may be free or monetized by their creator.
Plugins will be stored in their own repositories based on a plugin template repository. The plugin template repository will contain defined interfaces required for interoperability with the core.
¶ 3.2.1 Data Analysis Plugins
The impact of effective and detailed analysis is:
- The discovery of root causes of disease
- Development of new interventions
- The precise and personalized application of these interventions
Data Analysis Plugins will apply statistical and machine learning methods to the ocean of high-frequency longitudinal individual and population-level data. The resulting value will include:
- Personalized Effectiveness Quantification - Determination of the precise effectiveness of treatments for specific individuals
- Root Cause Analyses - Revelation of hidden factors and root causes of diseases
- Precision Medicine - Determination of the personalized optimal values or dosages based on biomarkers, phenotype, and demographics
- Combinatorial Medicine - Discover relationships between variables or combinations of interventions
- Effect Size Quantification - Quantification of effect sizes of all factors on symptom severity
- Optimal Daily Values - Determination of the personalized optimal dosages of nutrients or medications
- Cost-Benefit Analysis - Determination of the most cost-effective interventions by weight clinical benefit against costs in terms of side effects and financial impact
This will mitigate the incidence of chronic illnesses by informing the user of symptom triggers, such as dietary sensitivities, to be avoided. This will also assist patients and clinicians in assessing the effectiveness of treatments despite the hundreds of uncontrollable variables in any prescriptive experiment.
Large cohort clinical analysis could reveal new molecules for longevity.
¶ 3.2.2 Data Presentation and Management Plugins
Data visualization plugins convert data from its raw form into useful insights. They may be used to display data from individual or multiple subjects. Some regular ways to visualize data are scatter plots, timeline charts, heatmaps, or novel ways like the in the following proposed outcome labels. Visualizations can be embedded in studies, publications, or personal dashboards.
Tasks of data visualization plugins:
- Query the database according to filters and sorting commands
- Handle the processing of data processing functions like statistical analysis
Example Data Presentation Plugins
- Outcome Labels
- Predictor Search Engines
- Root Cause Analysis Reports
- Observational Studies
- Real-Time Decision Support Notifications
¶ 3.2.3 Application Programming Interface (API) Connector Plugins
Many applications and service providers offer a direct exchange of structured health data through an API, which upon user authentication allow access to automated and scheduled exports of the generated data.
So far the proprietary silo developments have produced many different data formats, which could be replaced with the data standard proposed within this project. Until the success of a common language for all types of health data and between all stakeholders, many API connecting plugins are necessary for this interoperability.
An API connector plugin handles:
- User interface and tokens for authentication and authorization with the 3rd party applications
- Automation and the periodic fetching of health data
- Mapping to the standard specification
- Providing the responses to the origin raw storage module
- error handling
- communication with the user
Connector Technical Flow
API Connector plugins will be called by the webserver to:
- Handle the OAuth2 authorization flow and store their credentials in the relational database
- Provide the original raw response to the core platform for encryption and storage
A job scheduler will call the API connectors periodically (usually daily) to:
- Refresh the user's OAuth access token
- Fetch new data or data that has been modified since the last import
- Map the response to the standard format as defined by the OpenAPI specification for the framework API
- Provide the processed data to the framework's validation middleware.
- All valid data will be stored in the relational database.
- Invalid data will be rejected and the plugin developer and data owner will be notified.
¶ 3.2.4 File Importers
File importing plugins are needed for specific sources or devices, where APIs are not available and the user only has access to raw files. Types of files include spreadsheets, PDFs, and raw genomic data.
- The file passed by an upload action to the data importer plugin user interface on the frontend application
- The core framework will encrypt and store the raw file
- The file ID and importer plugin ID will be added to a queue for processing by the job scheduler
The background job scheduler will:
- Retrieve the file from the encrypted storage
- Pass the file to the matching file importer plugin
- The importer plugin will extract the data from the file
- The importer plugin will map to the standard format as defined by the framework OpenAPI specification
- The processed data will be provided to the framework's validation middleware.
- Valid data will be stored in the relational database.
- Invalid data from the importer plugin will be rejected and the plugin developer and data owner will be notified.
A link between the created structured data and the original file allows backup and reprocessing (e.g. if the data import plugin functionality is expanded in future versions).
Challenges include changing proprietary formats, spreadsheet column matching, long upload times with raw files like from genomic testing.